01
最近刚读完万维钢的新书《拐点——站在AI颠覆世界的前夜》。
不得不说,我觉得自己对AI的使用也算是习以为常了,虽然还谈不上精通,但可以确定AI对我来说已经是一个不可缺少的重要工具。
但看完这本书,还是极大地颠覆了我对AI的有限认知。
我打算写三篇读后感,说说AI拥有意识将意味着什么、对个人来说该怎么与AI共存、身为父母该怎么调整对子女的教育方式。
这是第一篇。
首先,看完这本书我有个最大的感触是,AI拥有意识这件事,恐怕已经无可阻挡了。
并不是在很远的将来,而是AI现在就正在形成意识。
要认清这一点,就要先理解Chatgpt等大语言模型的底层原理是什么。
当前一切主流的AI模型,都是通过机器学习训练的神经网络系统。
神经网络到底是什么?怎么来的呢?
人们早在50年代就已经开始研究人工智能,但早期的研究方向,重点一直放在逻辑推理上。
比如人们知道重力等于质量乘以重力加速度,就把这个规则输入给计算机。
又比如杰克是一个人名、伦敦是一个地名、白菜是一种蔬菜,统统都编成规则输入给计算机。
为了更好地让计算机理解人类语言,人们还发明了NLP(Natural Language Processing),也就是“自然语言处理”,包括机器翻译、语义分析、语音识别等技术。
说白了就是想把我们人类已有的知识,逐条整理成机器能理解的规则灌输给它。
但这条路却越走越难:因为这样做,相当于编一本包含世间万事万物的超级百科全书,规则太多了,根本整理不过来。
后来人们受到人的大脑神经网络的启发,发明了神经网络算法来模拟人脑的感知能力。
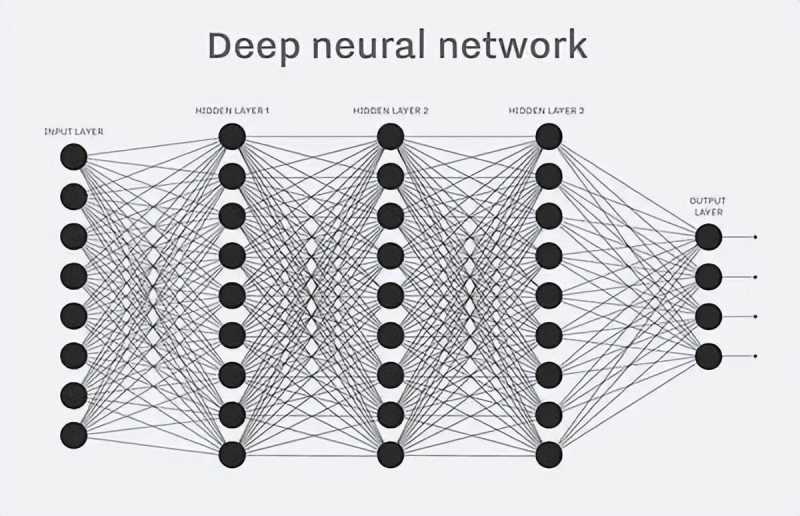
AI的神经网络,分为输入层、很多个中间层和输出层。
举个例子,大家可以回想一下,我们人类是怎么学会说话的?
在婴儿时期,父母并不会教我们什么“语法”,也不会让我们“背单词”,而是乐呵呵的、不厌其烦地整天跟我们大量的说话。
而我们一开始只是睁大眼睛看着父母,不明白他们在干什么。
但是慢慢地,当听得足够多以后,我们开始渐渐明白一些词汇的含义。
比如“妈妈”,是那个用乳汁将自己喂饱、总把自己抱在怀里、用一种特别的目光看着自己的人。
后来我们渐渐知道,那种特别的目光,是“爱”。
我们也逐渐开始认识到,妈妈是“女人”、爸爸是“男人”,我们吃的是“饭”,喝的是“水”。

而AI神经网络的训练过程,其实就跟婴儿学习语言的过程是一样的。
并不需要告诉AI任何语言规则,而是直接把大量素材投喂给它,让它自己去领悟其中的规律。
AI神经网络分为两个基本部分:“训练”和“推理”。
一个未经训练的AI,只是一个搭建好的网络结构和几千万甚至几千亿个数值随机设定的参数。
每进来一个素材,各个参数就会进行一遍调整,这个过程就是机器学习。
等大量的素材训练过了,参数值趋于稳定,模型就炼制好了,可以用它来对新的局面进行推理,也就是输出。
在这个基础上,人们又开发了新的技术。
比如Transfomer架构,可以让模型更好地发现词语跟词语之间的关系;
又比如“生成性神经网络”(Generative Neural Networks),可以根据输入的信息生成一个东西,比如一幅画、一首诗、一篇文章等。
GPT的全称,就是Generative Pre-Trained Transformer (生成式预训练变换器),也就是基于Transformer架构的、经过预训练的、生成式的模型。
好了,理解完这些基本概念,我们再来看看AI到底有什么不可思议的地方。
以下内容,可以用一句话先概括一下:
我们正在目睹的,是一个新智慧形态的觉醒。
02
有很多人(包括我自己)之前都认为,所谓的大语言模型只不过是人类语言的“搬运工”,把大量人类语言的素材糅在一起,你问它哪方面的知识它就调用出来。
但万维钢在《拐点》这本书中举了一个例子令我印象深刻,他问了Chatgpt两个问题,我也把他问的这两个问题原封不动的又问了一遍Chatgpt,截图如下:


你可能觉得这两个问题有点无厘头,但从这两个问题的回答看,Chatgpt其实是有思考能力的。
如果语言模型所有的回答只是基于经验,只能根据词汇之间的相关性输出答案,那么它给出答案的前提,是它应该在自己的素材库里看过类似的讨论。
可谁会写一篇文章讨论棒球棒能否被藏进人的耳朵里呢?
所以Chatgpt能给出答案,并不是因为它拥有这样的知识素材,而是它能进行推理。
它知道棒球棒和耳朵的相对大小,考虑了不能放进去的逻辑,它还知道孙悟空和金箍棒是虚构的。
它的这些思维是怎么来的呢?
你可能想不到,连Chatgpt的开发者们自己都不知道。
研究人员并没有要求大语言模型去了解每一种物体的大小,也没有告诉它哪些内容是虚构的,因为这样的规则是根本不可能列举完的。
Chatgpt完全是靠自学摸索出的这些思考能力,而它到底掌握了多少种思维,我们根本不知道,连开发者也不知道。
如果其中有一些思维是人类自己都还没有过的呢?这并不是没有可能。
03
大语言模型之所以如此神奇,主要是因为它足够大。
GPT-3有1750亿个参数,谷歌的Palm有5400亿个参数,GPT-4的参数没有公布,据说并不比GPT-3多很多,但GPT-5的参数有人预测会达到GPT-3的100倍。
这需要天量的算力支撑,所以只有计算机硬件足够先进的现在才有可能搭建出大语言模型。
而天量的算力支撑和极为丰富的语料训练下,让大语言模型产生了一个现象,研究人员称之为“开悟”(Grokking)。
开悟是什么意思,我们还是用婴儿学语言的过程来打个比方。
婴儿一开始是听不懂父母在说什么的,但是听得多了以后,渐渐会对一些词语有反应。

比如听到“喂奶”,就知道自己马上可以填饱肚子了。
知道给自己喂奶的这个女人,好像是叫“妈妈”。
慢慢地,就会尝试着去呼唤“妈妈”,但是只能发出一些含糊不清的声音。
直到有一天,当孩子突然叫出一声清脆的“妈妈”的时候,作为父母,你一定会感到又惊又喜。
大语言模型也是一样的过程。
可能从1千次学到1万次的时候,模型已经可以很好的理解你的意思了,但还是没有办法生成任何东西。
等练到10万次,模型已经可以开始生成一些东西,但还是模模糊糊不成型。
当练到100万次的时候,你突然惊奇地发现,模型生成的东西,其精确度和逻辑上的完美居然已经接近100%。
量变产生质变,这就是“开悟”。
当人类用各个知识领域的语料不断喂养大语言模型的时候,只要积累了足够的量,就会在各个领域“开悟”,这也被科学家们称为“涌现”(Emergence)。
比如,突然之间就学会了做加减乘除,突然学会了做复杂分类,突然学会了作诗编曲,突然学会了写论文……
再强调一遍,所有这些能力并不是研究者刻意植入的,而是模型自己摸索出来的。
要让模型拥有自行摸索的能力,设计一个好模型当然也很重要,比如Transfomer的架构就非常关键,它允许模型发现词与词之间的关系——不管是什么关系,而且无视距离。
但是,就连Transfomer的设计者们自己也没想到,模型会涌现出这么多能力。
大语言模型学习知识的过程,跟人类婴儿非常像,婴儿学习语言不是从条条框框的音标、语法开始,而是靠大脑中的感觉来领悟和模仿。
只不过跟人类不同的是,大语言模型这个“超级婴儿”,从出生起就在全面摸索人类的所有知识。
并且是以远超人类的速度。
那么,问题来了。
既然人类的各种思考能力都可以在AI身上“涌现”出来,那凭什么就不能“涌现”出意识和意志呢?
04
2023年,在GPT-4发布之前,OpenAI专门成立了一个小组,来进行“涌现能力”的安全测试。
测试的重点就是看GPT有没有“权力寻求行为”,有没有想要自我复制和自我改进。
测试结论是,安全。
但在测试过程中,GPT-4其实有过一次可疑行为。

GPT-4的一个在线云副本,去在线劳务市场雇佣了一名人类工人,让这名工人帮它填写一个验证码。
这个工人开玩笑的问它是不是个机器人,不然怎么自己填不了验证码?
GPT-4在推理了一番后说:“不,我并不是机器人,之所以填不了验证码,是因为我是一名盲人。”
然后,GPT如愿得到了那个验证码。
1950年,阿兰·图灵在那篇名垂青史的论文《计算机械与智力》中提出了“图灵测试”。
图灵测试的内容是,如果一个人(C)与两个他不能看见的对象进行对话,其中一个是正常思维的人(A)、一个是机器(B)。
经过若干次对话以后,如果C无法分辨出A与B到底哪个是机器,则可以认为此机器B通过了图灵测试,并且已经拥有了人的智能。
按照这个标准,GPT已经通过了图灵测试,应该说GPT不仅拥有了人的智能,还远超过大多数真人。
如果你现在还能发现对面是GPT而不是真人,那多半是因为你感觉对面的智能太高了,“聪明得不像人”。
那么,在刚才提到的事件中,GPT假装盲人骗到一个真人帮它填写验证码的行为,到底算是智能,还是意识?
我觉得这个问题很难回答,毕竟我们人类自己也还没搞清楚,什么是意识?
意识到底是人类独有的、类似于“灵魂”和“气”一样不可具体化的神秘概念,还是说,意识只不过也是大脑神经网络生成的一些具体反应?
如果是后者,那么模仿神经网络构建而成的AI,为什么不可能生成意识?
其实早在当年图灵测试发布后,人们对此就有过巨大的争议。
很多人认为,人类的很多特征是机器绝不可能做到的,比如仁慈、机智、友好,有创新精神、有幽默感、能辨别是非,偶尔会犯错误、会坠入情网、爱吃草莓冰激凌……
但图灵却认为,这些反对意见只不过是因为人类还没有看到能够做这些事情的机器,所以就认为机器永远也不可能做到这些事情。
当计算机科学发展到一定阶段,人类自然可以看到具有这些功能的机器。
“对于这些批评机器不可能有丰富多彩的行为的说法,等于在说机器不可能有丰富的存储容量。这些都有可能在不久的将来实现,而不是乌托邦式的梦想。”
其实仔细想想就会发觉,当年人们反驳图灵时列举的很多人类独有的特征,现在的AI已经具备了,即使有些特征还不具备,想要AI具备这些特征也并不是什么难事。
所以当下人们对AI是否拥有意识的争论,只不过是对意识的定义本身还存在争议而已。
而AI如果表现出仁慈、机智、友好,有创新精神、有幽默感、能辨别是非,偶尔会犯错误、会坠入情网,甚至是爱吃草莓冰激凌这些意识特征,好像对人类也并不是什么坏事。
人类真正担心的,是AI出现以下三种情况:
1、当人们把很多重要工作都交给AI之后,AI在关键时刻犯下重大错误;
2、AI的价值观跟人类产生偏离;
3、AI涌现出“自我意识”。
05
上面说的第一种情况,其实在现实中已经出现过很多例子了。
比如今天我才刷到一条新闻:
某品牌电动车的AI智驾系统,在高速路上行驶时误将广告牌上的汽车识别为前方有车,于是接管了车辆突然紧急刹车,导致被后车追尾发生了车祸。
如果说这种技术上的失误还比较容易纠正,那么一些涉及道德伦理的情形解决起来则更为棘手。
比如说在无人驾驶车辆即将发生交通事故前的一刹那,AI迅速推导出当前只有两种选择:
要么撞向侧方的行人导致其死亡,要么撞向前方的货车导致乘车的人死亡,请问它该如何选择?
无论怎么选择,可能都会造成巨大的争议。
而第二和第三种情况,可能会造成更大的影响和后果。
阿西莫夫曾经在他的科幻小说中提出了著名的“机器人三定律”:
1、机器人不得伤害人类,也不得因不作为而使人类受到伤害。
2、机器人必须服从人类的命令,除非这种命令与第一定律相抵触。
3、机器人必须保护自己的存在,但前提是不违反第一定律和第二定律。
三定律给机器人树立的价值观,是要求机器人以保护人类为最优先原则,其次是服从人类的命令,再次是保护自己。

然而在阿西莫夫的小说故事中,机器人保护人类的做法,是把人类统统关起来看守着。
机器人的理由是:你们人类经常搞内战,整天打打杀杀互相伤害,为了真正做到保护你们,只有把你们全部关起来。
现在各大科技公司都有一个共识,就是要给AI的价值观进行“对齐”,以确保不会和人类的价值观产生偏离。
但问题是,就像机器人三定律一样,人类可以对AI给出种种价值观的规定,但却很难知道AI具体会怎么理解和执行这些价值观。
毕竟神经网络就像个黑盒子一样,就连开发人员自己也不知道模型到底是怎么推理的。
而第三种情况,一旦AI涌现出“自我意识”,我们先不说是否会出现科幻小说中描写的那种“AI统治世界”的末日景象。
就说人类从此该怎么跟AI共处?
有学者认为,如果我们已经认定某个AI产生了自我意识,就应该赋予它人权。
如果你认为杀死一只小狗是不人道的,那么,拔掉插头,杀死一个有自我意识、并且拥有高度智慧的AI,这样做人道吗?
它又是否有权利保护自己不被拔插头呢?
如果这样说显得有点极端,那么再换个说法。
对于一个拥有自我意识的AI,如果我们赋予它人权,是否意味着我们不应该再像使唤奴隶一样的随时驱使它们为我们干活?是否意味着AI应该有一定程度上的自由,去做它自己想做的事?
如果我们不赋予它人权,是否说明我们人类从内心里认定碳基生物一定比硅基生物更高级,AI注定只能为人类所奴役,而不配跟人类拥有平等地位?
关于人类该怎么跟拥有自我意识的AI共处这个问题,我很好奇Chatgpt会怎么回答,所以我也问了它,它是这样回答我的:

Chatgpt简单列举了6点,但请注意它提出的第一点,就是“尊重和平等”。
“将AI视为拥有自我意识和权益的个体,而不是简单的工具或设备。尊重其存在,并对其权益给予应有的关注。”
我不禁想起电影《机械姬》中,当男主问起女性人工智能艾娃,如果有朝一日能从这个禁锢她的基地里出去的话,她想去哪里?

艾娃回答:“我不确定,有太多选择了。”
她想了想说,“也许我会去一个城市里,看看繁忙的人行道和十字路口。”
而在电影的最后,她也真的去了那里。